3 Ways of Categorical Variable Encoding
本篇文章主要介紹處理Categorical Data 常用的encoding技巧,同時以進階高數量類別特徵(high-cardinality)的資料作示範,這次的資料是由Amazon提供,可於kaggle下載。

我們在日常生活中碰到的數據千奇百種,通常也都會有文字或者亂碼,將其登記為數字(例如:士林區為1,北投區為2)的過程就稱為 Encoding,本篇會介紹三種Encoding 的方式,分別為:
1. Label encoding
2. One hot encoding
3. Target encoding (smooth mean with noise)
5. ROLE_DEPTNAME : 公司角色部門描述(例如零售)
6. ROLE_TITLE : 公司角色企業名稱說明(例如,高級工程零售經理)
7. ROLE_FAMILY_DESC : 員工類別擴展描述 (例如 軟體工程的零售經理)
8. ROLE_FAMILY : 員工類別 (例如 零售經理)
9. ROLE_CODE : 員工角色編碼 (例如 經理)
資料長這樣:

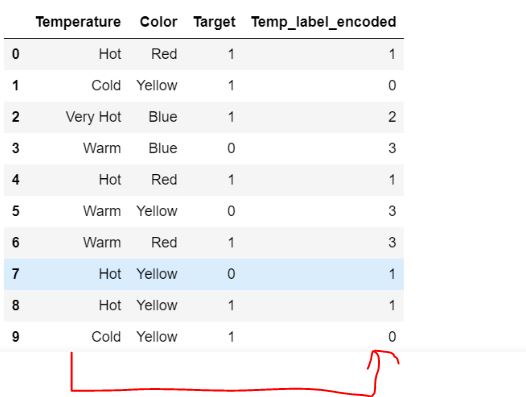



先以Mean encoding 作為例子簡介一下
X0的a 在10筆資料中出現5次,
5次裡又有4次為1,
因此 4/5 = 0.8即為他的Mean;
所以b 的 Mean 為 1/5 = 0.2
BANG~~~~
轉成量化的方式就是
把unique的值出現的次數與目標變數的結果做group by 的平均而已。
BUT!
就是這個BUT!
我們來看看X1的d,
只出現1次而且為0,
沒辦法判別他真的只是運氣不好還是分類為d就是只能為0
"很明顯當unique值出現越少,我們其實越不能去相信它"
我們不能相信出現頻率太少的平均值。
2. Overfitting
很簡單,每個a的個案經過Mean的轉換後,值會一樣,資料量大起來,大家又長的一樣,可能就沒有辦法建出類推性強的模型了
w = Total mean
上述的公式融入了target的總平均以達smooth 的效果,解決了少數unique的困境。
2. add noise
透過smooth 轉換而來的編碼,仍然長得一模一樣,還是會有overfit的風險,而且也不符合抽樣原則,所以加入高斯噪音調整!

Smooth mean:
Add noise:

結果大致如上了,Label效果最好,不過這沒有絕對的好與壞,還是把資料實驗看看會比較好~
參考:
https://maxhalford.github.io/blog/target-encoding-done-the-right-way/
https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
https://github.com/YLTsai0609/High-Cardinality-Categorical-Featue-Handling
何謂Categorical Data?何謂Encoding?
Categorical Data其實蠻簡單,就是測量尺度中的nominal 與 ordinal

Nominal : 只能用來比較相等或者不相等,而不能比較大小,更不能用來進行四則算術運算。
eg : 男女 / 貓狗牛 / 蔡英文、川普 / 編號89757、編號666
Ordinal : 類別有一定的順序或大小。次序尺度的變量之間除比較是否相等外,還可以比較大小。但是,加減乘除的運算仍然不能用在次序尺度中。
eg : 很滿意~很不滿意 / 開心~ 不爽
我們在日常生活中碰到的數據千奇百種,通常也都會有文字或者亂碼,將其登記為數字(例如:士林區為1,北投區為2)的過程就稱為 Encoding,本篇會介紹三種Encoding 的方式,分別為:
1. Label encoding
2. One hot encoding
3. Target encoding (smooth mean with noise)
本次Data: Amazon員工訪問權限
該數據包含從2010年和2011年收集的歷史數據。隨著時間的推移,會手動允許或拒絕員工Access資源。目標是建立一個準確預測Access的模型,好節省一來一往申請Access的時間!
Data Feature:
1. Action: 目標,1 = approved / 0 = deny
2. Resource : 資源ID
3. MGR_ID : 員工主管的ID
4. ROLE_ROLLUP_1 / ROLE_ROLLUP_2 : 公司角色分組類別ID 1 / 25. ROLE_DEPTNAME : 公司角色部門描述(例如零售)
6. ROLE_TITLE : 公司角色企業名稱說明(例如,高級工程零售經理)
7. ROLE_FAMILY_DESC : 員工類別擴展描述 (例如 軟體工程的零售經理)
8. ROLE_FAMILY : 員工類別 (例如 零售經理)
9. ROLE_CODE : 員工角色編碼 (例如 經理)
Having a Look!
tr <- read_csv("train.csv")
dim(tr)
sapply(tr,function(x) length(unique(x))) #count unique
> dim(tr)
[1] 32769 10
> sapply(tr,function(x) length(unique(x))) #count unique
ACTION RESOURCE MGR_ID ROLE_ROLLUP_1
2 7518 4243 128
ROLE_ROLLUP_2 ROLE_DEPTNAME ROLE_TITLE ROLE_FAMILY_DESC
177 449 343 2358
ROLE_FAMILY ROLE_CODE
67 343
一共32769筆資料,每一個變數的類別基本上都很多,其中resource更是高達7518種....資料長這樣:

Label encoding
其實很好理解,把不同的值分別編碼為1,2,3等數字,如果是有次序可以排名的話可以按照邏輯排列下去(又可以稱作Ordinal Encoding),下圖為例:

現在用R實踐:
邏輯其實蠻簡單,As integer 就可以幫我們編碼好了,但要記得再加一個factor(),這樣才仍然會是以factor的狀態執行model
Labeltr<- tr
for(i in c(2:10)){
Labeltr[, i] <- factor(Labeltr[[i]]) %>% as.integer() %>% factor()}
長這樣:

One hot encoding , OHE (In sparse matrix)
延續上一個範例,把每一個項目都拉出來做為獨立的variable,並登記為1

In R:
OHEtr<-sparsify(data.table(tr[,2:10]))
*考考各位,我們知道現在已知每個變數unique的值,請問最後出來會有幾個variable?
答案是所有unique值加起來後再加1,15626+1=15627

多一個的原因可能是因為截距項,讓你多一行出來
Sparse Matrix原理跟OHE一樣,以1,0為編碼,不同的是sparse把0轉為 .
可以節省許多運算空間以增進效率而且不會影響準確度
#筆者用OHE親自跑過模型,CPU基本上都是使用99%~100%在跑....而且狂當機,因此改為sparse
Target encoding (Mean encoding to smooth mean)
先說說Target encoding的意涵,基本上就是把類別變數轉換為數值變數(not ordinal but numerical),怎麼做呢?先以Mean encoding 作為例子簡介一下
| 1 | ||
| 1 | ||
| 1 | ||
| 1 | ||
| 0 | ||
| 1 | ||
| 0 | ||
| 0 | ||
| 0 | ||
| 0 |
5次裡又有4次為1,
因此 4/5 = 0.8即為他的Mean;
所以b 的 Mean 為 1/5 = 0.2
BANG~~~~
轉成量化的方式就是
把unique的值出現的次數與目標變數的結果做group by 的平均而已。
BUT!
就是這個BUT!
它也有其缺點:
1. 個體出現次數太少...我們來看看X1的d,
只出現1次而且為0,
沒辦法判別他真的只是運氣不好還是分類為d就是只能為0
"很明顯當unique值出現越少,我們其實越不能去相信它"
我們不能相信出現頻率太少的平均值。
2. Overfitting
很簡單,每個a的個案經過Mean的轉換後,值會一樣,資料量大起來,大家又長的一樣,可能就沒有辦法建出類推性強的模型了
怎麼解決?
1. Smooth mean
舉個例子 : 一部新電影在IMDB上發布了,並且獲得了三個評分。
這三個平均得分為9.5。這是蠻異常的事情,大多數電影往往會徘徊在7左右,而優秀電影很少會超過8。
因此我們斷定前三個評分是無法信任的極端值, 怎麼做呢?
訣竅是通過所有電影的平均評分來Smooth 一下平均的結果。
數學式如下:
μ=n+mn×xˉ+m×w
μ = smooth mean
n = number of values
x-bar = mean encode的mean
m = “weight” you want to assign to the overall meanw = Total mean
上述的公式融入了target的總平均以達smooth 的效果,解決了少數unique的困境。
2. add noise
透過smooth 轉換而來的編碼,仍然長得一模一樣,還是會有overfit的風險,而且也不符合抽樣原則,所以加入高斯噪音調整!
Demo in R:
以資料集中的Resource為例:
Mean encoding:
#Mean Encoding
colnames(tr)
Meanttr <- tr %>%
group_by(RESOURCE)%>%
mutate(targetmean2 = mean(ACTION))
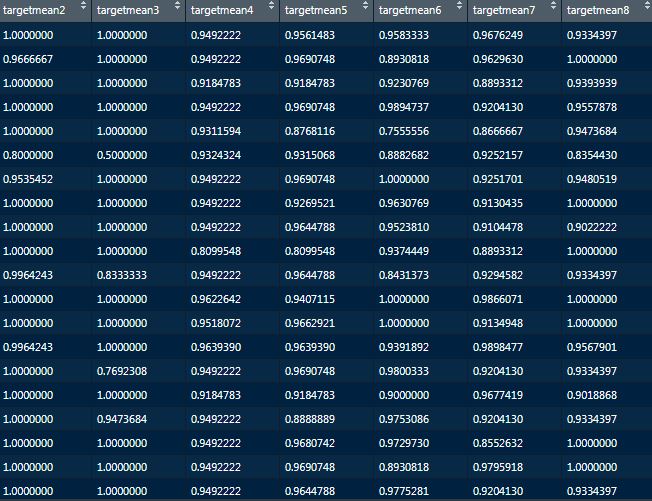
Smooth mean:
#smoothmean- Resource
n <- Targettr %>% group_by(RESOURCE) %>% count()
w <- mean(Targettr$ACTION)
RESOURCE <- Targettr[,c(2,11)]
RESOURCE %<>% left_join(n,by = "RESOURCE") %>%
mutate(smooth2 = (n*targetmean2+10*w)/n+10)
Add noise:
Noisify <- function(data) {
if (is.vector(data)) {
noise <- runif(length(data), 0, 1)
noisified <- data + noise
} else {
length <- dim(data)[1] * dim(data)[2]
noise <- matrix(runif(length, 0, 1), dim(data)[1])
noisified <- data + noise
}
return(noisified)
}
smoothnoise <-Noisify(smoothmean[,2:10])

Modeling:
一樣丟Xgboost吧
Labelxgb <- xgb.DMatrix(data.matrix(Labeltr[,-1]), label=Labeltr$ACTION)
OHExgb <- xgb.DMatrix(OHEtr,label = Labeltr$ACTION)
smoothxgb <- xgb.DMatrix(as.matrix(smoothnoise[,-10]), label=Labeltr)
#xgb-parameter
p <- list( booster = "gbtree",
objective = "reg:logistic",
eval_metric = "auc",
max_depth = 8 ,
eta = .05, #.05
subsample=1,
colsample_bytree=0.8,
num_boost_round=500,
nrounds = 300)
#label encoding model
Label<- xgb.cv( params = p,
data = Labelxgb,
nfold = 5,
nrounds=300,
early_stopping_rounds = 100,
print_every_n = 20)
#Smoothmean
smooth<- xgb.cv( params = p,
data = smoothxgb,
nfold = 5,
nrounds=300,
early_stopping_rounds = 100,
print_every_n = 20)
#OHE model
OHE <- xgb.cv( params = p,
data = OHExgb,
nfold = 5,
nrounds=300,
early_stopping_rounds = 100,
print_every_n = 20)
| Encoding | AUC on validation set |
|---|---|
| One-Hot | 0.816 |
| Label | 0.845 |
| Target | 0.788 |
結果大致如上了,Label效果最好,不過這沒有絕對的好與壞,還是把資料實驗看看會比較好~
https://maxhalford.github.io/blog/target-encoding-done-the-right-way/
https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
https://github.com/YLTsai0609/High-Cardinality-Categorical-Featue-Handling



留言
張貼留言